Black lives matter.
We stand in solidarity with the Black community.
Racism is unacceptable.
It conflicts with the core values of the Kubernetes project and our community does not tolerate it.
We stand in solidarity with the Black community.
Racism is unacceptable.
It conflicts with the core values of the Kubernetes project and our community does not tolerate it.
Kubernetes 1.5 [alpha]
您可以在谷歌计算引擎(GCE)的 kubeup 或 kube-down 脚本中复制 Kubernetes Master。
本文描述了如何使用 kube-up/down 脚本来管理高可用(HA)的 Master,以及如何使用 GCE 实现高可用 Master。
你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 如果你还没有集群,你可以通过 Minikube 构建一 个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建:
要获知版本信息,请输入kubectl version.
要创建一个新的兼容高可用的集群,您必须在 kubeup 脚本中设置以下标志:
MULTIZONE=true - 为了防止从不同于 Master 默认区域的区域中删除 kubelets 副本。如果您希望在不同的区域运行 Master 副本,那么这一项是必需并且推荐的。
ENABLE_ETCD_QUORUM_READ=true - 确保从所有 API 服务器读取数据时将返回最新的数据。如果为 true,读操作将被定向到 leader etcd 副本。可以选择将这个值设置为 true,那么读取将更可靠,但也会更慢。
您还可以指定一个 GCE 区域,在这里创建第一个 Master 副本。设置以下标志:
KUBE_GCE_ZONE=zone - 将运行第一个 Master 副本的区域。下面的命令演示在 GCE europe-west1-b 区域中设置一个兼容高可用的集群:
MULTIZONE=true KUBE_GCE_ZONE=europe-west1-b ENABLE_ETCD_QUORUM_READS=true ./cluster/kube-up.sh
注意,上面的命令创建一个只有单一 Master 的集群; 但是,您可以使用后续命令将新的 Master 副本添加到集群中。
在创建了兼容高可用的集群之后,可以向其中添加 Master 副本。
您可以使用带有如下标记的 kubeup 脚本添加 Master 副本:
KUBE_REPLICATE_EXISTING_MASTER=true - 创建一个已经存在的 Master 的副本。
KUBE_GCE_ZONE=zone - Master 副本将运行的区域。必须与其他副本位于同一区域。
您无需设置 MULTIZONE 或 ENABLE_ETCD_QUORUM_READS 标志,因为他们可以从兼容高可用的集群中继承。
使用下面的命令可以复制现有兼容高可用的集群上的 Master:
KUBE_GCE_ZONE=europe-west1-c KUBE_REPLICATE_EXISTING_MASTER=true ./cluster/kube-up.sh
你可以使用一个 kube-down 脚本从高可用集群中删除一个 Master 副本,并可以使用以下标记:
KUBE_DELETE_NODES=false - 限制删除 kubelets。
KUBE_GCE_ZONE=zone - 将移除 Master 副本的区域。
KUBE_REPLICA_NAME=replica_name - (可选)要删除的 Master 副本的名称。
如果为空:将删除给定区域中的所有副本。
使用下面的命令可以从一个现有的高可用集群中删除一个 Master副本:
KUBE_DELETE_NODES=false KUBE_GCE_ZONE=europe-west1-c ./cluster/kube-down.sh
如果高可用集群中的一个 Master 副本失败,最佳实践是从集群中删除副本,并在相同的区域中添加一个新副本。 下面的命令演示了这个过程:
KUBE_DELETE_NODES=false KUBE_GCE_ZONE=replica_zone KUBE_REPLICA_NAME=replica_name ./cluster/kube-down.sh
KUBE_GCE_ZONE=replica-zone KUBE_REPLICATE_EXISTING_MASTER=true ./cluster/kube-up.sh
尝试将 Master 副本放置在不同的区域。在某区域故障时,放置在该区域内的所有主机都将失败。 为了在区域故障中幸免,请同样将工作节点放置在多区域中(详情请见多区域)。
不要使用具有两个 Master 副本的集群。在双副本集群上达成一致需要在更改持久状态时两个副本都处于运行状态。因此,两个副本都是需要的,任一副本的失败都会将集群带入多数失败状态。因此,就高可用而言,双副本集群不如单个副本集群。
添加 Master 副本时,集群状态(etcd)会被复制到一个新实例。如果集群很大,可能需要很长时间才能复制它的状态。 这个操作可以通过迁移 etcd 数据存储来加速, 详情参见 这里 (我们正在考虑在未来添加对迁移 etcd 数据存储的支持)。
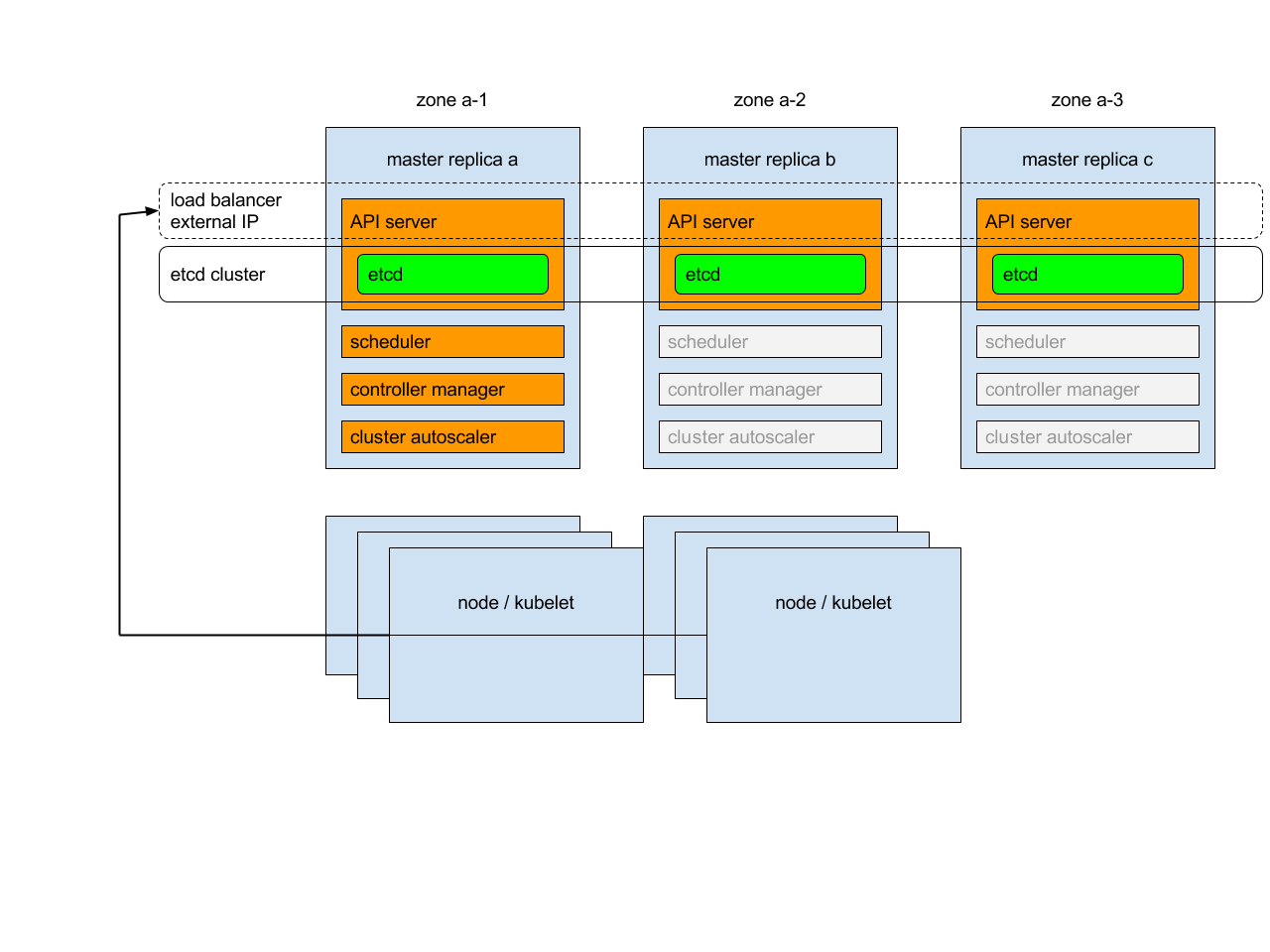
每个 Master 副本将以以下模式运行以下组件:
etcd 实例: 所有实例将会以共识方式组建集群;
API 服务器: 每个服务器将与本地 etcd 通信——集群中的所有 API 服务器都可用;
控制器、调度器和集群自动扩缩器:将使用租约机制 —— 每个集群中只有一个实例是可用的;
add-on manager:每个管理器将独立工作,试图保持插件同步。
此外,在 API 服务器前面将有一个负载均衡器,用于将外部和内部通信路由到他们。
启动第二个 Master 副本时,将创建一个包含两个副本的负载均衡器,并将第一个副本的 IP 地址提升为负载均衡器的 IP 地址。 类似地,在删除倒数第二个 Master 副本之后,将删除负载均衡器,并将其 IP 地址分配给最后一个剩余的副本。 请注意,创建和删除负载均衡器是复杂的操作,可能需要一些时间(约20分钟)来同步。
Kubernetes 并不试图在其服务中保持 apiserver 的列表为最新,相反,它将将所有访问请求指向外部 IP:
在拥有一个 Master 的集群中,IP 指向单一的 Master,
在拥有多个 Master 的集群中,IP 指向 Master 前面的负载均衡器。
类似地,kubelets 将使用外部 IP 与 Master 通信。
Kubernetes 为每个副本的外部公共 IP 和本地 IP 生成 Master TLS 证书。 副本的临时公共 IP 没有证书; 要通过其临时公共 IP 访问副本,必须跳过TLS验证。
为了允许 etcd 组建集群,需开放 etcd 实例之间通信所需的端口(用于集群内部通信)。 为了使这种部署安全,etcd 实例之间的通信使用 SSL 进行鉴权。