Black lives matter.
We stand in solidarity with the Black community.
Racism is unacceptable.
It conflicts with the core values of the Kubernetes project and our community does not tolerate it.
We stand in solidarity with the Black community.
Racism is unacceptable.
It conflicts with the core values of the Kubernetes project and our community does not tolerate it.
Kubernetes v1.5 [alpha]
구글 컴퓨트 엔진(Google Compute Engine, 이하 GCE)의 kube-up이나 kube-down 스크립트에 쿠버네티스 마스터를 복제할 수 있다.
이 문서는 kube-up/down 스크립트를 사용하여 고가용(HA) 마스터를 관리하는 방법과 GCE와 함께 사용하기 위해 HA 마스터를 구현하는 방법에 관해 설명한다.
쿠버네티스 클러스터가 필요하고, kubectl 커맨드-라인 툴이 클러스터와 통신할 수 있도록 설정되어 있어야 한다. 만약, 아직 클러스터를 가지고 있지 않다면, Minikube를 사용해서 생성하거나, 다음의 쿠버네티스 플레이그라운드 중 하나를 사용할 수 있다.
버전 확인을 위해서, 다음 커맨드를 실행kubectl version.
새 HA 호환 클러스터를 생성하려면, kube-up 스크립트에 다음 플래그를 설정해야 한다.
MULTIZONE=true - 서버의 기본 존(zone)과 다른 존에서 마스터 복제본의 kubelet이 제거되지 않도록 한다.
다른 존에서 마스터 복제본을 실행하려는 경우에 권장하고 필요하다.
ENABLE_ETCD_QUORUM_READ=true - 모든 API 서버에서 읽은 내용이 최신 데이터를 반환하도록 하기 위한 것이다.
true인 경우, Etcd의 리더 복제본에서 읽는다.
이 값을 true로 설정하는 것은 선택 사항이다. 읽기는 더 안정적이지만 느리게 된다.
선택적으로 첫 번째 마스터 복제본이 생성될 GCE 존을 지정할 수 있다. 다음 플래그를 설정한다.
KUBE_GCE_ZONE=zone - 첫 마스터 복제본이 실행될 존.다음 샘플 커맨드는 europe-west1-b GCE 존에 HA 호환 클러스터를 구성한다.
MULTIZONE=true KUBE_GCE_ZONE=europe-west1-b ENABLE_ETCD_QUORUM_READS=true ./cluster/kube-up.sh
위에 커맨드는 하나의 마스터로 클러스터를 생성한다. 그러나 후속 커맨드로 새 마스터 복제본을 추가할 수 있다.
HA 호환 클러스터를 생성한 다음 그것의 마스터 복제본을 추가할 수 있다.
kube-up 스크립트에 다음 플래그를 사용하여 마스터 복제본을 추가한다.
KUBE_REPLICATE_EXISTING_MASTER=true - 기존 마스터의 복제본을
만든다.
KUBE_GCE_ZONE=zone - 마스터 복제본이 실행될 존.
반드시 다른 복제본 존과 동일한 존에 있어야 한다.
HA 호환 클러스터를 시작할 때, 상속되는 MULTIZONE이나 ENABLE_ETCD_QUORUM_READS 플래그를 따로
설정할 필요는 없다.
다음 샘플 커맨드는 기존 HA 호환 클러스터에서 마스터를 복제한다.
KUBE_GCE_ZONE=europe-west1-c KUBE_REPLICATE_EXISTING_MASTER=true ./cluster/kube-up.sh
다음 플래그가 있는 kube-down 스크립트를 사용하여 HA 클러스터에서 마스터 복제본을 제거할 수 있다.
KUBE_DELETE_NODES=false - kubelet을 삭제하지 않기 위한 것이다.
KUBE_GCE_ZONE=zone - 마스터 복제본이 제거될 존.
KUBE_REPLICA_NAME=replica_name - (선택) 제거할 마스터 복제본의 이름.
비어있는 경우, 해당 존의 모든 복제본이 제거된다.
다음 샘플 커맨드는 기존 HA 클러스터에서 마스터 복제본을 제거한다.
KUBE_DELETE_NODES=false KUBE_GCE_ZONE=europe-west1-c ./cluster/kube-down.sh
HA 클러스터의 마스터 복제본 중 하나가 실패하면, 클러스터에서 복제본을 제거하고 동일한 존에서 새 복제본을 추가하는 것이 가장 좋다. 다음 샘플 커맨드로 이 과정을 시연한다.
손상된 복제본을 제거한다.
KUBE_DELETE_NODES=false KUBE_GCE_ZONE=replica_zone KUBE_REPLICA_NAME=replica_name ./cluster/kube-down.sh
기존 복제본 대신 새 복제본을 추가한다.
KUBE_GCE_ZONE=replica-zone KUBE_REPLICATE_EXISTING_MASTER=true ./cluster/kube-up.sh
다른 존에 마스터 복제본을 배치하도록 한다. 한 존이 실패하는 동안, 해당 존에 있는 마스터도 모두 실패할 것이다. 존 장애를 극복하기 위해 노드를 여러 존에 배치한다 (더 자세한 내용은 멀티 존를 참조한다).
두 개의 마스터 복제본은 사용하지 않는다. 두 개의 복제 클러스터에 대한 합의는 지속적 상태를 변경해야 할 때 두 복제본 모두 실행해야 한다. 결과적으로 두 복제본 모두 필요하고, 어떤 복제본의 장애에도 클러스터가 대부분 장애 상태로 변한다. 따라서 두 개의 복제본 클러스터는 HA 관점에서 단일 복제 클러스터보다 열등하다.
마스터 복제본을 추가하면, 클러스터의 상태(Etcd)도 새 인스턴스로 복사된다. 클러스터가 크면, 이 상태를 복제하는 시간이 오래 걸릴 수 있다. 이 작업은 여기 기술한 대로 Etcd 데이터 디렉터리를 마이그레이션하여 속도를 높일 수 있다(향후에 Etcd 데이터 디렉터리 마이그레이션 지원 추가를 고려 중이다).
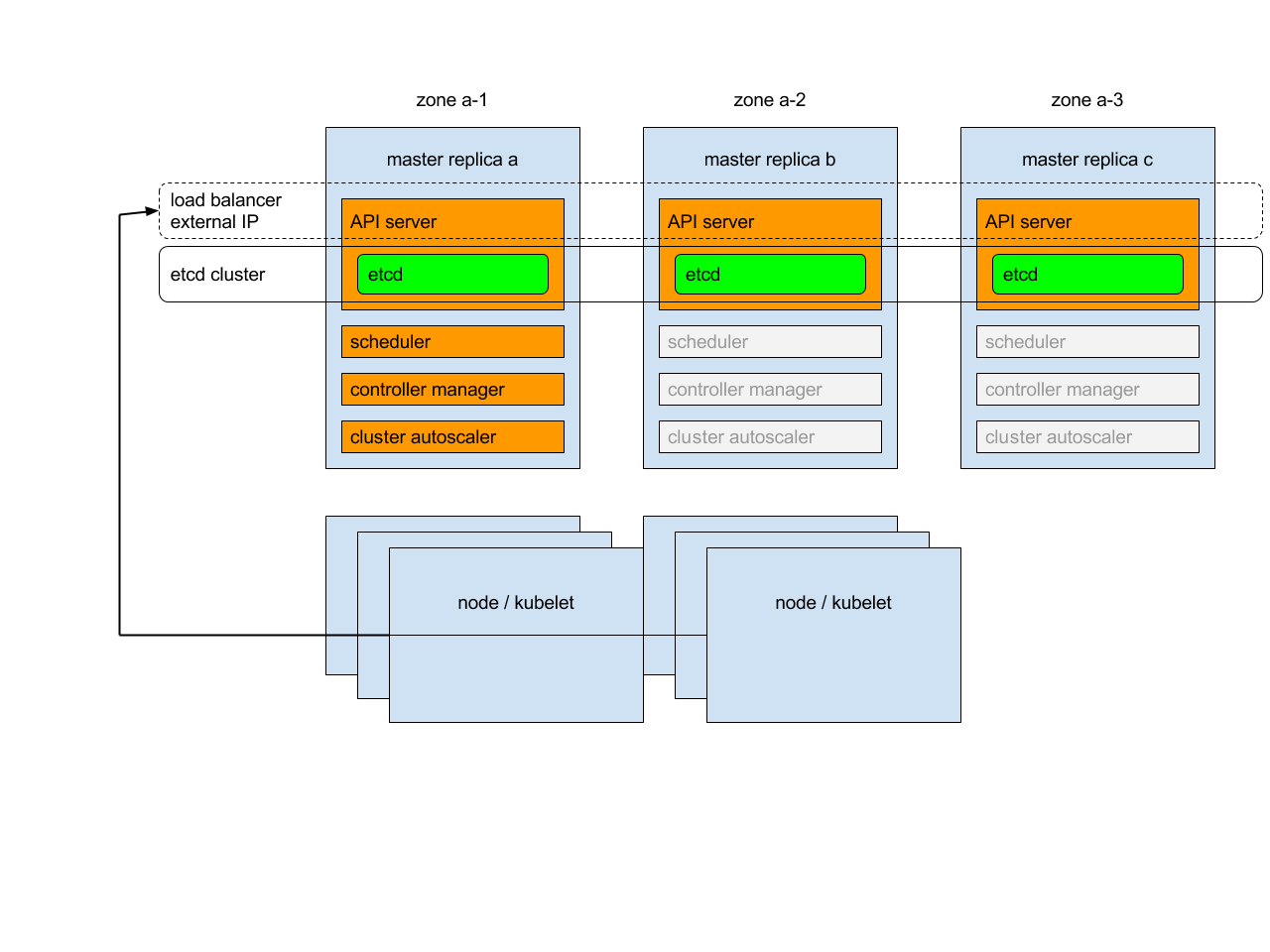
각 마스터 복제본은 다음 모드에서 다음 구성 요소를 실행한다.
Etcd 인스턴스: 모든 인스턴스는 합의를 사용하여 함께 클러스터화 한다.
API 서버: 각 서버는 내부 Etcd와 통신한다. 클러스터의 모든 API 서버가 가용하게 된다.
컨트롤러, 스케줄러, 클러스터 오토스케일러: 임대 방식을 이용한다. 각 인스턴스 중 하나만이 클러스터에서 활성화된다.
애드온 매니저: 각 매니저는 애드온의 동기화를 유지하려고 독립적으로 작업한다.
또한 API 서버 앞단에 외부/내부 트래픽을 라우팅하는 로드 밸런서가 있을 것이다.
두 번째 마스터 복제본을 시작할 때, 두 개의 복제본을 포함된 로드 밸런서가 생성될 것이고, 첫 번째 복제본의 IP 주소가 로드 밸런서의 IP 주소로 승격된다. 비슷하게 끝에서 두 번째의 마스터 복제본을 제거한 후에는 로드 밸런서가 제거되고 해당 IP 주소는 마지막으로 남은 복제본에 할당된다. 로드 밸런서 생성 및 제거는 복잡한 작업이며, 이를 전파하는 데 시간(~20분)이 걸릴 수 있다.
쿠버네티스 서비스에서 최신의 쿠버네티스 API 서버 목록을 유지하는 대신, 시스템은 모든 트래픽을 외부 IP 주소로 보낸다.
단일 마스터 클러스터에서 IP 주소는 단일 마스터를 가리킨다.
다중 마스터 클러스터에서 IP 주소는 마스터 앞에 로드밸런서를 가리킨다.
마찬가지로 Kubelet은 외부 IP 주소를 사용하여 마스터와 통신한다.
쿠버네티스는 각 복제본의 외부 퍼블릭 IP 주소와 내부 IP 주소를 대상으로 마스터 TLS 인증서를 발급한다. 복제본의 임시 공개 IP 주소에 대한 인증서는 없다. 임시 퍼블릭 IP 주소를 통해 복제본에 접근하려면, TLS 검증을 건너뛰어야 한다.
etcd를 클러스터로 구축하려면, etcd 인스턴스간 통신에 필요한 포트를 열어야 한다(클러스터 내부 통신용). 이러한 배포를 안전하게 하기 위해, etcd 인스턴스간의 통신은 SSL을 이용하여 승인한다.